Leeloo Quadruple (4x) Simple Moving AverageOne-stop shop for all of the simple moving averages because editing separately is annoying.
Cari skrip untuk "one一季度财报"

ATR stop and threshold valueOne can use the average true range for both entries and stops. A possible way to reduce false breakouts is to enter (say) at 0.5 * atr above the breakout level. Then you could use a 1.0*atr for a stop setting. This indicator allows you to set entries and stops for both long and short setups directly on the chart. I use it with breakout systems as it allows me to easily setup my trades.

Multiple Simple Moving AveragesOne no-fuss indicator for SMA for 6 different time period (10, 20, 50, 100, 200, 250), styled with sharp and thin line for shorter time period to light-coloured and wide line for longer time period.

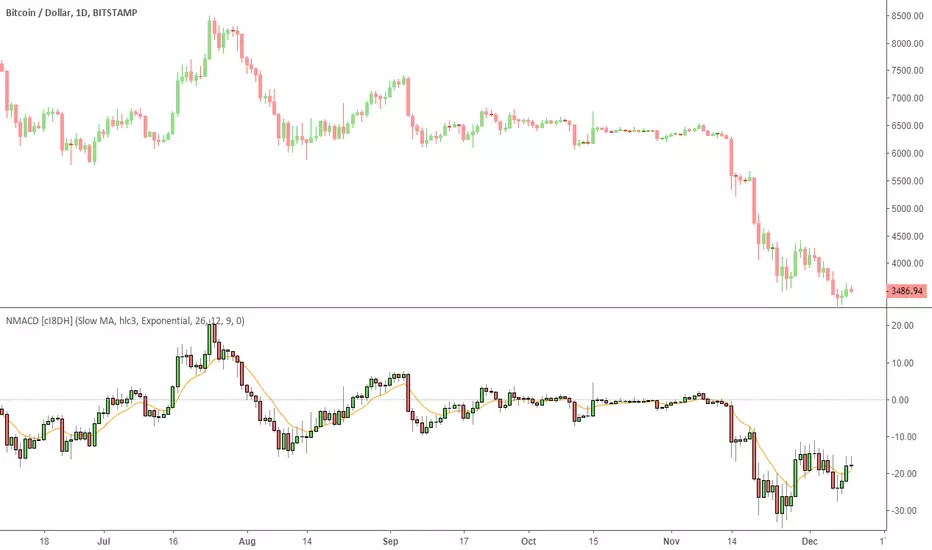
Multi Color Normalized MACD + Candles (NMACD) [cI8DH]One simple indicator for volatility, divergence and relative momentum
Features:
- Normalized MACD (by slow MA)
- Candle MACD (fast MA length is set to 0 in candle mode, i.e. price minus slow MA)
- Multi color histogram
- Background coloring based on MACD direction
- Choice of different MA types (Exponential, Simple, Weighted, Smoothed, Triple EMA)
- Triple EMA smoothing
Benefits of normalization:
- Absolutely better than RSI for comparing across different periods and assets
Applications and benefits of candle visualization:
- Zero cross: most traders use MAs overlaid on the main chart and look for price distance and MA cross visually. In candle mode, this indicator measures the difference between price and the slow moving MA. When this indicator crosses zero, it means price is crossing the slow moving MA.
- Divergence: full candle visualization (OHLC) is not possible for most other indicators. Candle visualization allows measuring divergence between price high, low and close simultaneously. Some trades incorrectly measure divergence between high, low of price against indicator tops and bottoms while having the indicator input set to default (usually close). With this indicator, you don't need to worry about such complexities.
Recommended setting:
- Enjoy candle mode :)
- Source set to hlc3
Fibonacci Exponential Moving Averages (+ 200EMA)One indicator to rule them all...
So here you have the fib based EMA`s (8,3,21,55) plus I added the 200 EMA cause I love it and should give you the complete picture. Have fun!
To add click on "Add to favorite scripts" and then select in your TV settings.
*Thanks to behind_crypto for publishing the base version of the script!*
EMA50Diff & MACD StrategyOne of my attempts to create a strategy for BTC.
Its a combination of EMA50Diff (the difference between spot and EMA50) and MACD.
Buy signal if (EMA50Diff) < -(EMADiffThreshold),
(MACD bearish crossunder),
(MACD) < -(MACDThreshold),
(EMA50Diff) > (EMA50Diff 1 candle ago),
(EMA50Diff 1 candle ago) < (EMA50Diff 2 candles ago)
Sell signal if (EMA50Diff) > (EMADiffThreshold),
(MACD bullish crossover),
(MACD) > (MACDThreshold),
(EMA50Diff) < (EMA50Diff 1 candle ago),
(EMA50Diff 1 candle ago) > (EMA50Diff 2 candles ago)
Exit either when target or stoploss get reached.
Initial capital is set to 100k and its currently going all-in on every trade but im looking for a better way to handle position sizes already..
Also i included slippage of 30 ticks and exchange commission of 0.15% (e.g. 2x BitMEX market taker fee)
Works best on 15m on bitfinex, bitstamp and gdax and i'm still trying to optimize it for bitmex too, will update when i got there..

RSI / Stoch / Stoch RSI (SRSI) Overlay [SigmaDraconis]One indicator combining RSI, Stochastic Oscillator and Stochastic RSI in one.
Credits for rwhiteside and his RSI / Stoch RSI Overlay indicator who served as inspiration to all three.
I believe this will be very useful to a lot of people.
If you like, use and i prove to be , you can contribute to my
TIP JAR :

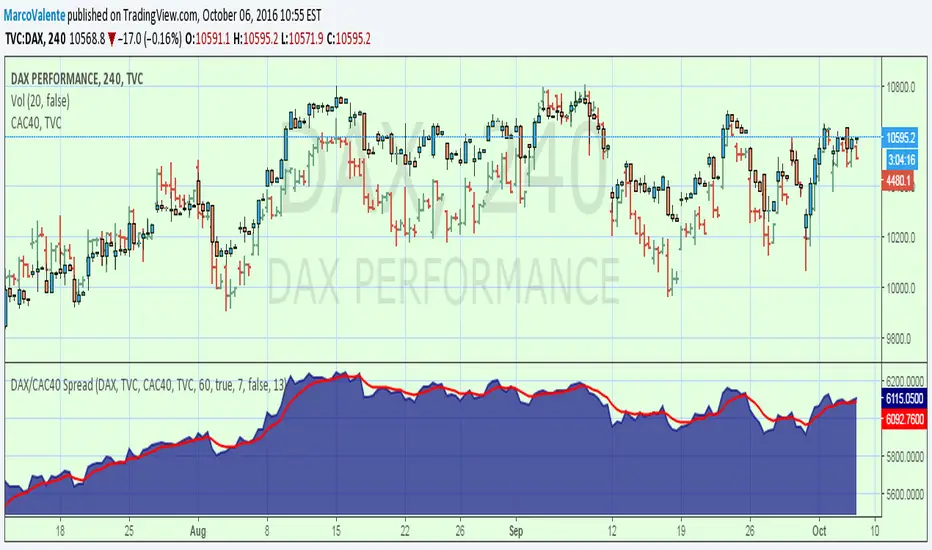
DAX/CAC40 SpreadOne more spread. You can change symbol by click on the input symbol window, and use anyone you like
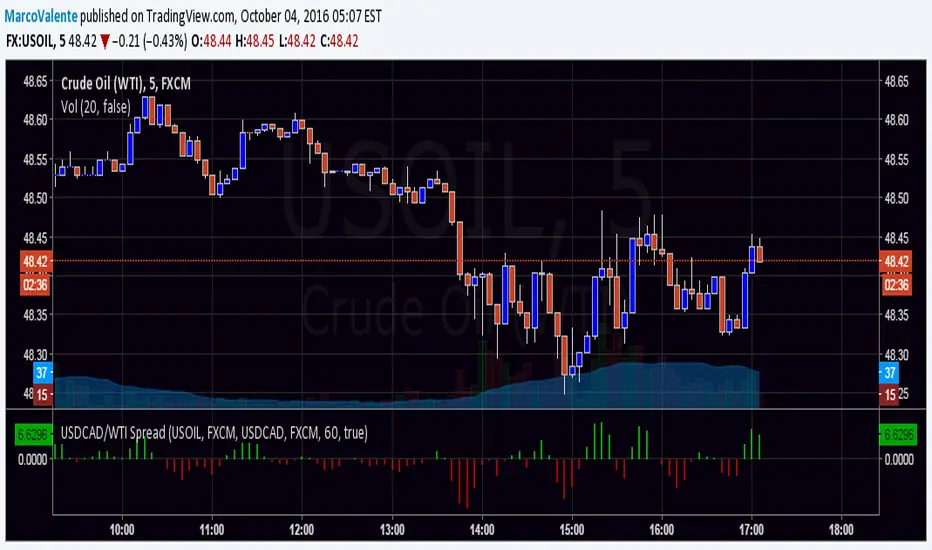
USDCAD/WTI SpreadOne more spread , this is USDCAD/WTI . Is the change of the moment of this 2 security.
One White Soldier StudyThis shows a green indicator on this study (17Jun & 15Aug on TRN) when a bullish candle opens and closes above the prior day's bearish candle, ignoring gap ups. This will only show in the DAILY chart, not intraday.

Ehlers Simple Cycle Indicator [LazyBear]One of the early cycle indicators from John Ehlers.
Ehlers suggests using this with ITrend (see linked PDF below). Osc/signal crosses identify entry/exit points.
Options page has the usual set of configurable params.
More info:
- Simple Cycle Indicator: www.mesasoftware.com
List of my public indicators: bit.ly
List of my app-store indicators: blog.tradingview.com

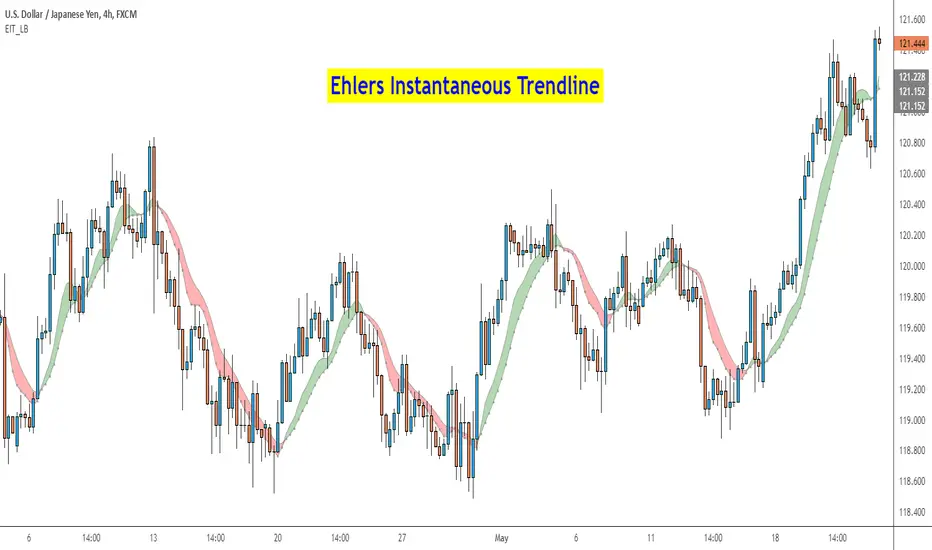
Ehlers Instantaneous Trend [LazyBear]One more to add to the Ehlers collection.
Ehlers Instantaneous Trendline, by John Ehlers, identifies the market trend by doing removing cycle component. I think, this simplicity is what makes it attractive :) To understand Ehlers's thought process behind this, refer to the PDF linked below.
There are atleast 6 variations of this ITrend. This version is from his early presentations.
Is this better than a simple HMA? May be, May be not. I will leave it to you to decide :)
I have added options to show this as a ribbon, and to color bars based on ITrend. Check out the options page.
More info:
- ITrend: www.mesasoftware.com
List of my public indicators: bit.ly
List of my app-store indicators: blog.tradingview.com
Linear Moments█ OVERVIEW
The Linear Moments indicator, also known as L-moments, is a statistical tool used to estimate the properties of a probability distribution. It is an alternative to conventional moments and is more robust to outliers and extreme values.
█ CONCEPTS
█ Four moments of a distribution
We have mentioned the concept of the Moments of a distribution in one of our previous posts. The method of Linear Moments allows us to calculate more robust measures that describe the shape features of a distribution and are anallougous to those of conventional moments. L-moments therefore provide estimates of the location, scale, skewness, and kurtosis of a probability distribution.
The first L-moment, λ₁, is equivalent to the sample mean and represents the location of the distribution. The second L-moment, λ₂, is a measure of the dispersion of the distribution, similar to the sample standard deviation. The third and fourth L-moments, λ₃ and λ₄, respectively, are the measures of skewness and kurtosis of the distribution. Higher order L-moments can also be calculated to provide more detailed information about the shape of the distribution.
One advantage of using L-moments over conventional moments is that they are less affected by outliers and extreme values. This is because L-moments are based on order statistics, which are more resistant to the influence of outliers. By contrast, conventional moments are based on the deviations of each data point from the sample mean, and outliers can have a disproportionate effect on these deviations, leading to skewed or biased estimates of the distribution parameters.
█ Order Statistics
L-moments are statistical measures that are based on linear combinations of order statistics, which are the sorted values in a dataset. This approach makes L-moments more resistant to the influence of outliers and extreme values. However, the computation of L-moments requires sorting the order statistics, which can lead to a higher computational complexity.
To address this issue, we have implemented an Online Sorting Algorithm that efficiently obtains the sorted dataset of order statistics, reducing the time complexity of the indicator. The Online Sorting Algorithm is an efficient method for sorting large datasets that can be updated incrementally, making it well-suited for use in trading applications where data is often streamed in real-time. By using this algorithm to compute L-moments, we can obtain robust estimates of distribution parameters while minimizing the computational resources required.
█ Bias and efficiency of an estimator
One of the key advantages of L-moments over conventional moments is that they approach their asymptotic normal closer than conventional moments. This means that as the sample size increases, the L-moments provide more accurate estimates of the distribution parameters.
Asymptotic normality is a statistical property that describes the behavior of an estimator as the sample size increases. As the sample size gets larger, the distribution of the estimator approaches a normal distribution, which is a bell-shaped curve. The mean and variance of the estimator are also related to the true mean and variance of the population, and these relationships become more accurate as the sample size increases.
The concept of asymptotic normality is important because it allows us to make inferences about the population based on the properties of the sample. If an estimator is asymptotically normal, we can use the properties of the normal distribution to calculate the probability of observing a particular value of the estimator, given the sample size and other relevant parameters.
In the case of L-moments, the fact that they approach their asymptotic normal more closely than conventional moments means that they provide more accurate estimates of the distribution parameters as the sample size increases. This is especially useful in situations where the sample size is small, such as when working with financial data. By using L-moments to estimate the properties of a distribution, traders can make more informed decisions about their investments and manage their risk more effectively.
Below we can see the empirical dsitributions of the Variance and L-scale estimators. We ran 10000 simulations with a sample size of 100. Here we can clearly see how the L-moment estimator approaches the normal distribution more closely and how such an estimator can be more representative of the underlying population.
█ WAYS TO USE THIS INDICATOR
The Linear Moments indicator can be used to estimate the L-moments of a dataset and provide insights into the underlying probability distribution. By analyzing the L-moments, traders can make inferences about the shape of the distribution, such as whether it is symmetric or skewed, and the degree of its spread and peakedness. This information can be useful in predicting future market movements and developing trading strategies.
One can also compare the L-moments of the dataset at hand with the L-moments of certain commonly used probability distributions. Finance is especially known for the use of certain fat tailed distributions such as Laplace or Student-t. We have built in the theoretical values of L-kurtosis for certain common distributions. In this way a person can compare our observed L-kurtosis with the one of the selected theoretical distribution.
█ FEATURES
Source Settings
Source - Select the source you wish the indicator to calculate on
Source Selection - Selec whether you wish to calculate on the source value or its log return
Moments Settings
Moments Selection - Select the L-moment you wish to be displayed
Lookback - Determine the sample size you wish the L-moments to be calculated with
Theoretical Distribution - This setting is only for investingating the kurtosis of our dataset. One can compare our observed kurtosis with the kurtosis of a selected theoretical distribution.

Grok/Claude Turtle Soup Strategy # 🥣 Turtle Soup Strategy (Enhanced)
## A Mean-Reversion Strategy Based on Failed Breakouts
---
## Historical Origins
### The Original Turtle Traders (1983-1988)
The Turtle Trading system is one of the most famous experiments in trading history. In 1983, legendary commodities trader **Richard Dennis** made a bet with his partner **William Eckhardt** about whether great traders were born or made. Dennis believed trading could be taught; Eckhardt believed it was innate.
To settle the debate, Dennis recruited 23 ordinary people through newspaper ads—including a professional blackjack player, a fantasy game designer, and an accountant—and taught them his trading system in just two weeks. He called them "Turtles" after turtle farms he had visited in Singapore, saying *"We are going to grow traders just like they grow turtles in Singapore."*
The results were extraordinary. Over the next five years, the Turtles reportedly earned over **$175 million in profits**. The experiment proved Dennis right: trading could indeed be taught.
#### The Original Turtle Rules:
- **Entry:** Buy when price breaks above the 20-day high (System 1) or 55-day high (System 2)
- **Exit:** Sell when price breaks below the 10-day low (System 1) or 20-day low (System 2)
- **Stop Loss:** 2x ATR (Average True Range) from entry
- **Position Sizing:** Based on volatility (ATR)
- **Philosophy:** Pure trend-following—catch big moves by riding breakouts
The Turtle system was a **trend-following** strategy that assumed breakouts would lead to sustained trends. It worked brilliantly in trending markets but suffered during choppy, range-bound conditions.
---
### The Turtle Soup Strategy (1990s)
In the 1990s, renowned trader **Linda Bradford Raschke** (along with Larry Connors) observed something interesting: many of the breakouts that the Turtle system traded actually *failed*. Price would spike above the 20-day high, trigger Turtle buy orders, then immediately reverse—trapping the breakout traders.
Raschke realized these failed breakouts were predictable and tradeable. She developed the **Turtle Soup** strategy, which does the *exact opposite* of the original Turtle system:
> *"Instead of buying the breakout, we wait for it to fail—then fade it."*
The name "Turtle Soup" is a clever play on words: the strategy essentially "eats" the Turtles by trading against them when their breakouts fail.
#### Original Turtle Soup Rules:
- **Setup:** Price makes a new 20-day high (or low)
- **Qualifier:** The previous 20-day high must be at least 3-4 days old (not a fresh breakout)
- **Entry Trigger:** Price reverses back inside the channel (failed breakout)
- **Entry:** Go SHORT (against the failed breakout above), or LONG (against the failed breakdown below)
- **Philosophy:** Mean-reversion—fade false breakouts and profit from trapped traders
#### Turtle Soup Plus One Variant:
Raschke also developed a more conservative variant called "Turtle Soup Plus One" which waits for the *next bar* after the breakout to confirm the failure before entering. This reduces false signals but may miss some opportunities.
---
## Our Enhanced Turtle Soup Strategy
We have taken the classic Turtle Soup concept and enhanced it with modern technical indicators and filters to improve signal quality and adapt to today's markets.
### Core Logic Preserved
The fundamental strategy remains true to Raschke's original concept:
| Turtle (Original) | Turtle Soup (Our Strategy) |
|-------------------|---------------------------|
| BUY breakout above 20-day high | SHORT when that breakout FAILS |
| SELL breakout below 20-day low | LONG when that breakdown FAILS |
| Trend-following | Mean-reversion |
| "The trend is your friend" | "Failed breakouts trap traders" |
---
### Enhancements & Improvements
#### 1. RSI Exhaustion Filter
**Addition:** RSI must confirm exhaustion before entry
- **For SHORT entries:** RSI > 60 (buyers exhausted)
- **For LONG entries:** RSI < 40 (sellers exhausted)
**Why:** The original Turtle Soup had no momentum filter. Adding RSI ensures we only fade breakouts when the market is showing signs of exhaustion, significantly reducing false signals. This enhancement was inspired by later traders who found RSI extremes (originally 90/10, softened to 60/40) dramatically improved win rates.
#### 2. ADX Trending Filter
**Addition:** ADX must be > 20 for trades to execute
**Why:** While the original Turtle Soup was designed for ranging markets, we found that requiring *some* trend strength (ADX > 20) actually improves results. This ensures we're trading in markets with enough directional movement to create meaningful failed breakouts, rather than random noise in dead markets.
#### 3. Heikin Ashi Smoothing
**Addition:** Optional Heikin Ashi calculations for breakout detection
**Why:** Heikin Ashi candles smooth out price noise and make trend reversals more visible. When enabled, the strategy uses HA values to detect breakouts and failures, reducing whipsaws from erratic price spikes.
#### 4. Dynamic Donchian Channels with Regime Detection
**Addition:** Color-coded channels based on market regime
- 🟢 **Green:** Bullish regime (uptrend + DI+ > DI- + OBV bullish)
- 🔴 **Red:** Bearish regime (downtrend + DI- > DI+ + OBV bearish)
- 🟡 **Yellow:** Neutral regime
**Why:** Visual regime detection helps traders understand the broader market context. The original Turtle Soup had no regime awareness—our enhancement lets traders see at a glance whether conditions favor the strategy.
#### 5. Volume Spike Detection (Optional)
**Addition:** Optional filter requiring volume surge on the breakout bar
**Why:** Failed breakouts are more significant when they occur on high volume. A volume spike on the breakout bar (default 1.2x average) indicates more traders got trapped, creating stronger reversal potential.
#### 6. ATR-Based Stops and Targets
**Addition:** Configurable ATR-based stop losses and profit targets
- **Stop Loss:** 1.5x ATR (default)
- **Profit Target:** 2.0x ATR (default)
**Why:** The original Turtle Soup used fixed stop placement. ATR-based stops adapt to current volatility, providing tighter stops in calm markets and wider stops in volatile conditions.
#### 7. Signal Cooldown
**Addition:** Minimum bars between trades (default 5)
**Why:** Prevents overtrading during choppy conditions where multiple failed breakouts might occur in quick succession.
#### 8. Real-Time Info Panel
**Addition:** Comprehensive dashboard showing:
- Current regime (Bullish/Bearish/Neutral)
- RSI value and zone
- ADX value and trending status
- Breakout status
- Bars since last high/low
- Current setup status
- Position status
**Why:** Gives traders instant visibility into all strategy conditions without needing to check multiple indicators.
---
## Entry Rules Summary
### SHORT Entry (Fading Failed Breakout Above)
1. ✅ Price breaks ABOVE the 20-period Donchian high
2. ✅ Previous 20-period high was at least 1 bar ago
3. ✅ Price closes back BELOW the Donchian high (failed breakout)
4. ✅ RSI > 60 (exhausted buyers)
5. ✅ ADX > 20 (trending market)
6. ✅ Cooldown period met
→ **Enter SHORT**, betting the breakout will fail
### LONG Entry (Fading Failed Breakdown Below)
1. ✅ Price breaks BELOW the 20-period Donchian low
2. ✅ Previous 20-period low was at least 1 bar ago
3. ✅ Price closes back ABOVE the Donchian low (failed breakdown)
4. ✅ RSI < 40 (exhausted sellers)
5. ✅ ADX > 20 (trending market)
6. ✅ Cooldown period met
→ **Enter LONG**, betting the breakdown will fail
---
## Exit Rules
1. **ATR Stop Loss:** Position closed if price moves 1.5x ATR against entry
2. **ATR Profit Target:** Position closed if price moves 2.0x ATR in favor
3. **Channel Exit:** Position closed if price breaks the exit channel in the opposite direction
4. **Mid-Channel Exit:** Position closed if price returns to channel midpoint
---
## Best Market Conditions
The Turtle Soup strategy performs best when:
- ✅ Markets are prone to false breakouts
- ✅ Volatility is moderate (not too low, not extreme)
- ✅ Price is oscillating within a broader range
- ✅ There are clear support/resistance levels
The strategy may struggle when:
- ❌ Strong trends persist (breakouts follow through)
- ❌ Volatility is extremely low (no meaningful breakouts)
- ❌ Markets are in news-driven directional moves
---
## Default Settings
| Parameter | Default | Description |
|-----------|---------|-------------|
| Lookback Period | 20 | Donchian channel period |
| Min Bars Since Extreme | 1 | Bars since last high/low |
| RSI Length | 14 | RSI calculation period |
| RSI Short Level | 60 | RSI must be above this for shorts |
| RSI Long Level | 40 | RSI must be below this for longs |
| ADX Length | 14 | ADX calculation period |
| ADX Threshold | 20 | Minimum ADX for trades |
| ATR Period | 20 | ATR calculation period |
| ATR Stop Multiplier | 1.5 | Stop loss distance in ATR |
| ATR Target Multiplier | 2.0 | Profit target distance in ATR |
| Cooldown Period | 5 | Minimum bars between trades |
| Volume Multiplier | 1.2 | Volume spike threshold |
---
## Philosophy
> *"The Turtle system made millions by following breakouts. The Turtle Soup strategy makes money when those breakouts fail. In trading, there's always someone on the other side of the trade—this strategy profits by being the smart money that fades the trapped breakout traders."*
The beauty of the Turtle Soup strategy is its elegant simplicity: it exploits a known, repeatable pattern (failed breakouts) while using modern filters (RSI, ADX) to improve timing and reduce false signals.
---
## Credits
- **Original Turtle System:** Richard Dennis & William Eckhardt (1983)
- **Turtle Soup Strategy:** Linda Bradford Raschke & Larry Connors (1990s)
- **RSI Enhancement:** Various traders who discovered RSI extremes improve reversal detection
- **This Implementation:** Enhanced with Heikin Ashi smoothing, regime detection, ADX filtering, and comprehensive visualization
---
*"We're not following the turtles—we're making soup out of them."* 🥣

Expected Move BandsExpected move is the amount that an asset is predicted to increase or decrease from its current price, based on the current levels of volatility.
In this model, we assume asset price follows a log-normal distribution and the log return follows a normal distribution.
Note: Normal distribution is just an assumption, it's not the real distribution of return
Settings:
"Estimation Period Selection" is for selecting the period we want to construct the prediction interval.
For "Current Bar", the interval is calculated based on the data of the previous bar close. Therefore changes in the current price will have little effect on the range. What current bar means is that the estimated range is for when this bar close. E.g., If the Timeframe on 4 hours and 1 hour has passed, the interval is for how much time this bar has left, in this case, 3 hours.
For "Future Bars", the interval is calculated based on the current close. Therefore the range will be very much affected by the change in the current price. If the current price moves up, the range will also move up, vice versa. Future Bars is estimating the range for the period at least one bar ahead.
There are also other source selections based on high low.
Time setting is used when "Future Bars" is chosen for the period. The value in time means how many bars ahead of the current bar the range is estimating. When time = 1, it means the interval is constructing for 1 bar head. E.g., If the timeframe is on 4 hours, then it's estimating the next 4 hours range no matter how much time has passed in the current bar.
Note: It's probably better to use "probability cone" for visual presentation when time > 1
Volatility Models :
Sample SD: traditional sample standard deviation, most commonly used, use (n-1) period to adjust the bias
Parkinson: Uses High/ Low to estimate volatility, assumes continuous no gap, zero mean no drift, 5 times more efficient than Close to Close
Garman Klass: Uses OHLC volatility, zero drift, no jumps, about 7 times more efficient
Yangzhang Garman Klass Extension: Added jump calculation in Garman Klass, has the same value as Garman Klass on markets with no gaps.
about 8 x efficient
Rogers: Uses OHLC, Assume non-zero mean volatility, handles drift, does not handle jump 8 x efficient
EWMA: Exponentially Weighted Volatility. Weight recently volatility more, more reactive volatility better in taking account of volatility autocorrelation and cluster.
YangZhang: Uses OHLC, combines Rogers and Garmand Klass, handles both drift and jump, 14 times efficient, alpha is the constant to weight rogers volatility to minimize variance.
Median absolute deviation: It's a more direct way of measuring volatility. It measures volatility without using Standard deviation. The MAD used here is adjusted to be an unbiased estimator.
Volatility Period is the sample size for variance estimation. A longer period makes the estimation range more stable less reactive to recent price. Distribution is more significant on a larger sample size. A short period makes the range more responsive to recent price. Might be better for high volatility clusters.
Standard deviations:
Standard Deviation One shows the estimated range where the closing price will be about 68% of the time.
Standard Deviation two shows the estimated range where the closing price will be about 95% of the time.
Standard Deviation three shows the estimated range where the closing price will be about 99.7% of the time.
Note: All these probabilities are based on the normal distribution assumption for returns. It's the estimated probability, not the actual probability.
Manually Entered Standard Deviation shows the range of any entered standard deviation. The probability of that range will be presented on the panel.
People usually assume the mean of returns to be zero. To be more accurate, we can consider the drift in price from calculating the geometric mean of returns. Drift happens in the long run, so short lookback periods are not recommended. Assuming zero mean is recommended when time is not greater than 1.
When we are estimating the future range for time > 1, we typically assume constant volatility and the returns to be independent and identically distributed. We scale the volatility in term of time to get future range. However, when there's autocorrelation in returns( when returns are not independent), the assumption fails to take account of this effect. Volatility scaled with autocorrelation is required when returns are not iid. We use an AR(1) model to scale the first-order autocorrelation to adjust the effect. Returns typically don't have significant autocorrelation. Adjustment for autocorrelation is not usually needed. A long length is recommended in Autocorrelation calculation.
Note: The significance of autocorrelation can be checked on an ACF indicator.
ACF
The multimeframe option enables people to use higher period expected move on the lower time frame. People should only use time frame higher than the current time frame for the input. An error warning will appear when input Tf is lower. The input format is multiplier * time unit. E.g. : 1D
Unit: M for months, W for Weeks, D for Days, integers with no unit for minutes (E.g. 240 = 240 minutes). S for Seconds.
Smoothing option is using a filter to smooth out the range. The filter used here is John Ehler's supersmoother. It's an advance smoothing technique that gets rid of aliasing noise. It affects is similar to a simple moving average with half the lookback length but smoother and has less lag.
Note: The range here after smooth no long represent the probability
Panel positions can be adjusted in the settings.
X position adjusts the horizontal position of the panel. Higher X moves panel to the right and lower X moves panel to the left.
Y position adjusts the vertical position of the panel. Higher Y moves panel up and lower Y moves panel down.
Step line display changes the style of the bands from line to step line. Step line is recommended because it gets rid of the directional bias of slope of expected move when displaying the bands.
Warnings:
People should not blindly trust the probability. They should be aware of the risk evolves by using the normal distribution assumption. The real return has skewness and high kurtosis. While skewness is not very significant, the high kurtosis should be noticed. The Real returns have much fatter tails than the normal distribution, which also makes the peak higher. This property makes the tail ranges such as range more than 2SD highly underestimate the actual range and the body such as 1 SD slightly overestimate the actual range. For ranges more than 2SD, people shouldn't trust them. They should beware of extreme events in the tails.
Different volatility models provide different properties if people are interested in the accuracy and the fit of expected move, they can try expected move occurrence indicator. (The result also demonstrate the previous point about the drawback of using normal distribution assumption).
Expected move Occurrence Test
The prediction interval is only for the closing price, not wicks. It only estimates the probability of the price closing at this level, not in between. E.g., If 1 SD range is 100 - 200, the price can go to 80 or 230 intrabar, but if the bar close within 100 - 200 in the end. It's still considered a 68% one standard deviation move.

️Omega RatioThe Omega Ratio is a risk-return performance measure of an investment asset, portfolio, or strategy. It is defined as the probability-weighted ratio, of gains versus losses for some threshold return target. The ratio is an alternative for the widely used Sharpe ratio and is based on information the Sharpe ratio discards.
█ OVERVIEW
As we have mentioned many times, stock market returns are usually not normally distributed. Therefore the models that assume a normal distribution of returns may provide us with misleading information. The Omega Ratio improves upon the common normality assumption among other risk-return ratios by taking into account the distribution as a whole.
█ CONCEPTS
Two distributions with the same mean and variance, would according to the most commonly used Sharpe Ratio suggest that the underlying assets of the distribution offer the same risk-return ratio. But as we have mentioned in our Moments indicator, variance and standard deviation are not a sufficient measure of risk in the stock market since other shape features of a distribution like skewness and excess kurtosis come into play. Omega Ratio tackles this problem by employing all four Moments of the distribution and therefore taking into account the differences in the shape features of the distributions. Another important feature of the Omega Ratio is that it does not require any estimation but is rather calculated directly from the observed data. This gives it an advantage over standard statistical estimators that require estimation of parameters and are therefore sampling uncertainty in its calculations.
█ WAYS TO USE THIS INDICATOR
Omega calculates a probability-adjusted ratio of gains to losses, relative to the Minimum Acceptable Return (MAR). This means that at a given MAR using the simple rule of preferring more to less, an asset with a higher value of Omega is preferable to one with a lower value. The indicator displays the values of Omega at increasing levels of MARs and creating the so-called Omega Curve. Knowing this one can compare Omega Curves of different assets and decide which is preferable given the MAR of your strategy. The indicator plots two Omega Curves. One for the on chart symbol and another for the off chart symbol that u can use for comparison.
When comparing curves of different assets make sure their trading days are the same in order to ensure the same period for the Omega calculations. Value interpretation: Omega<1 will indicate that the risk outweighs the reward and therefore there are more excess negative returns than positive. Omega>1 will indicate that the reward outweighs the risk and that there are more excess positive returns than negative. Omega=1 will indicate that the minimum acceptable return equals the mean return of an asset. And that the probability of gain is equal to the probability of loss.
█ FEATURES
• "Low-Risk security" lets you select the security that you want to use as a benchmark for Omega calculations.
• "Omega Period" is the size of the sample that is used for the calculations.
• “Increments” is the number of Minimal Acceptable Return levels the calculation is carried on. • “Other Symbol” lets you select the source of the second curve.
• “Color Settings” you can set the color for each curve.

Historical Volatility EstimatorsHistorical volatility is a statistical measure of the dispersion of returns for a given security or market index over a given period. This indicator provides different historical volatility model estimators with percentile gradient coloring and volatility stats panel.
█ OVERVIEW There are multiple ways to estimate historical volatility. Other than the traditional close-to-close estimator. This indicator provides different range-based volatility estimators that take high low open into account for volatility calculation and volatility estimators that use other statistics measurements instead of standard deviation. The gradient coloring and stats panel provides an overview of how high or low the current volatility is compared to its historical values.
█ CONCEPTS We have mentioned the concepts of historical volatility in our previous indicators, Historical Volatility, Historical Volatility Rank, and Historical Volatility Percentile. You can check the definition of these scripts. The basic calculation is just the sample standard deviation of log return scaled with the square root of time. The main focus of this script is the difference between volatility models.
Close-to-Close HV Estimator: Close-to-Close is the traditional historical volatility calculation. It uses sample standard deviation. Note: the TradingView build in historical volatility value is a bit off because it uses population standard deviation instead of sample deviation. N – 1 should be used here to get rid of the sampling bias.
Pros:
• Close-to-Close HV estimators are the most commonly used estimators in finance. The calculation is straightforward and easy to understand. When people reference historical volatility, most of the time they are talking about the close to close estimator.
Cons:
• The Close-to-close estimator only calculates volatility based on the closing price. It does not take account into intraday volatility drift such as high, low. It also does not take account into the jump when open and close prices are not the same.
• Close-to-Close weights past volatility equally during the lookback period, while there are other ways to weight the historical data.
• Close-to-Close is calculated based on standard deviation so it is vulnerable to returns that are not normally distributed and have fat tails. Mean and Median absolute deviation makes the historical volatility more stable with extreme values.
Parkinson Hv Estimator:
• Parkinson was one of the first to come up with improvements to historical volatility calculation. • Parkinson suggests using the High and Low of each bar can represent volatility better as it takes into account intraday volatility. So Parkinson HV is also known as Parkinson High Low HV. • It is about 5.2 times more efficient than Close-to-Close estimator. But it does not take account into jumps and drift. Therefore, it underestimates volatility. Note: By Dividing the Parkinson Volatility by Close-to-Close volatility you can get a similar result to Variance Ratio Test. It is called the Parkinson number. It can be used to test if the market follows a random walk. (It is mentioned in Nassim Taleb's Dynamic Hedging book but it seems like he made a mistake and wrote the ratio wrongly.)
Garman-Klass Estimator:
• Garman Klass expanded on Parkinson’s Estimator. Instead of Parkinson’s estimator using high and low, Garman Klass’s method uses open, close, high, and low to find the minimum variance method.
• The estimator is about 7.4 more efficient than the traditional estimator. But like Parkinson HV, it ignores jumps and drifts. Therefore, it underestimates volatility.
Rogers-Satchell Estimator:
• Rogers and Satchell found some drawbacks in Garman-Klass’s estimator. The Garman-Klass assumes price as Brownian motion with zero drift.
• The Rogers Satchell Estimator calculates based on open, close, high, and low. And it can also handle drift in the financial series.
• Rogers-Satchell HV is more efficient than Garman-Klass HV when there’s drift in the data. However, it is a little bit less efficient when drift is zero. The estimator doesn’t handle jumps, therefore it still underestimates volatility.
Garman-Klass Yang-Zhang extension:
• Yang Zhang expanded Garman Klass HV so that it can handle jumps. However, unlike the Rogers-Satchell estimator, this estimator cannot handle drift. It is about 8 times more efficient than the traditional estimator.
• The Garman-Klass Yang-Zhang extension HV has the same value as Garman-Klass when there’s no gap in the data such as in cryptocurrencies.
Yang-Zhang Estimator:
• The Yang Zhang Estimator combines Garman-Klass and Rogers-Satchell Estimator so that it is based on Open, close, high, and low and it can also handle non-zero drift. It also expands the calculation so that the estimator can also handle overnight jumps in the data.
• This estimator is the most powerful estimator among the range-based estimators. It has the minimum variance error among them, and it is 14 times more efficient than the close-to-close estimator. When the overnight and daily volatility are correlated, it might underestimate volatility a little.
• 1.34 is the optimal value for alpha according to their paper. The alpha constant in the calculation can be adjusted in the settings. Note: There are already some volatility estimators coded on TradingView. Some of them are right, some of them are wrong. But for Yang Zhang Estimator I have not seen a correct version on TV.
EWMA Estimator:
• EWMA stands for Exponentially Weighted Moving Average. The Close-to-Close and all other estimators here are all equally weighted.
• EWMA weighs more recent volatility more and older volatility less. The benefit of this is that volatility is usually autocorrelated. The autocorrelation has close to exponential decay as you can see using an Autocorrelation Function indicator on absolute or squared returns. The autocorrelation causes volatility clustering which values the recent volatility more. Therefore, exponentially weighted volatility can suit the property of volatility well.
• RiskMetrics uses 0.94 for lambda which equals 30 lookback period. In this indicator Lambda is coded to adjust with the lookback. It's also easy for EWMA to forecast one period volatility ahead.
• However, EWMA volatility is not often used because there are better options to weight volatility such as ARCH and GARCH.
Adjusted Mean Absolute Deviation Estimator:
• This estimator does not use standard deviation to calculate volatility. It uses the distance log return is from its moving average as volatility.
• It’s a simple way to calculate volatility and it’s effective. The difference is the estimator does not have to square the log returns to get the volatility. The paper suggests this estimator has more predictive power.
• The mean absolute deviation here is adjusted to get rid of the bias. It scales the value so that it can be comparable to the other historical volatility estimators.
• In Nassim Taleb’s paper, he mentions people sometimes confuse MAD with standard deviation for volatility measurements. And he suggests people use mean absolute deviation instead of standard deviation when we talk about volatility.
Adjusted Median Absolute Deviation Estimator:
• This is another estimator that does not use standard deviation to measure volatility.
• Using the median gives a more robust estimator when there are extreme values in the returns. It works better in fat-tailed distribution.
• The median absolute deviation is adjusted by maximum likelihood estimation so that its value is scaled to be comparable to other volatility estimators.
█ FEATURES
• You can select the volatility estimator models in the Volatility Model input
• Historical Volatility is annualized. You can type in the numbers of trading days in a year in the Annual input based on the asset you are trading.
• Alpha is used to adjust the Yang Zhang volatility estimator value.
• Percentile Length is used to Adjust Percentile coloring lookbacks.
• The gradient coloring will be based on the percentile value (0- 100). The higher the percentile value, the warmer the color will be, which indicates high volatility. The lower the percentile value, the colder the color will be, which indicates low volatility.
• When percentile coloring is off, it won’t show the gradient color.
• You can also use invert color to make the high volatility a cold color and a low volatility high color. Volatility has some mean reversion properties. Therefore when volatility is very low, and color is close to aqua, you would expect it to expand soon. When volatility is very high, and close to red, you would it expect it to contract and cool down.
• When the background signal is on, it gives a signal when HVP is very low. Warning there might be a volatility expansion soon.
• You can choose the plot style, such as lines, columns, areas in the plotstyle input.
• When the show information panel is on, a small panel will display on the right.
• The information panel displays the historical volatility model name, the 50th percentile of HV, and HV percentile. 50 the percentile of HV also means the median of HV. You can compare the value with the current HV value to see how much it is above or below so that you can get an idea of how high or low HV is. HV Percentile value is from 0 to 100. It tells us the percentage of periods over the entire lookback that historical volatility traded below the current level. Higher HVP, higher HV compared to its historical data. The gradient color is also based on this value.
█ HOW TO USE If you haven’t used the hvp indicator, we suggest you use the HVP indicator first. This indicator is more like historical volatility with HVP coloring. So it displays HVP values in the color and panel, but it’s not range bound like the HVP and it displays HV values. The user can have a quick understanding of how high or low the current volatility is compared to its historical value based on the gradient color. They can also time the market better based on volatility mean reversion. High volatility means volatility contracts soon (Move about to End, Market will cooldown), low volatility means volatility expansion soon (Market About to Move).
█ FINAL THOUGHTS HV vs ATR The above volatility estimator concepts are a display of history in the quantitative finance realm of the research of historical volatility estimations. It's a timeline of range based from the Parkinson Volatility to Yang Zhang volatility. We hope these descriptions make more people know that even though ATR is the most popular volatility indicator in technical analysis, it's not the best estimator. Almost no one in quant finance uses ATR to measure volatility (otherwise these papers will be based on how to improve ATR measurements instead of HV). As you can see, there are much more advanced volatility estimators that also take account into open, close, high, and low. HV values are based on log returns with some calculation adjustment. It can also be scaled in terms of price just like ATR. And for profit-taking ranges, ATR is not based on probabilities. Historical volatility can be used in a probability distribution function to calculated the probability of the ranges such as the Expected Move indicator. Other Estimators There are also other more advanced historical volatility estimators. There are high frequency sampled HV that uses intraday data to calculate volatility. We will publish the high frequency volatility estimator in the future. There's also ARCH and GARCH models that takes volatility clustering into account. GARCH models require maximum likelihood estimation which needs a solver to find the best weights for each component. This is currently not possible on TV due to large computational power requirements. All the other indicators claims to be GARCH are all wrong.

Hurst Exponent - Detrended Fluctuation AnalysisIn stochastic processes, chaos theory and time series analysis, detrended fluctuation analysis (DFA) is a method for determining the statistical self-affinity of a signal. It is useful for analyzing time series that appear to be long-memory processes and noise.
█ OVERVIEW
We have introduced the concept of Hurst Exponent in our previous open indicator Hurst Exponent (Simple). It is an indicator that measures market state from autocorrelation. However, we apply a more advanced and accurate way to calculate Hurst Exponent rather than simple approximation. Therefore, we recommend using this version of Hurst Exponent over our previous publication going forward. The method we used here is called detrended fluctuation analysis. (For folks that are not interested in the math behind the calculation, feel free to skip to "features" and "how to use" section. However, it is recommended that you read it all to gain a better understanding of the mathematical reasoning).
█ Detrend Fluctuation Analysis
Detrended Fluctuation Analysis was first introduced by by Peng, C.K. (Original Paper) in order to measure the long-range power-law correlations in DNA sequences . DFA measures the scaling-behavior of the second moment-fluctuations, the scaling exponent is a generalization of Hurst exponent.
The traditional way of measuring Hurst exponent is the rescaled range method. However DFA provides the following benefits over the traditional rescaled range method (RS) method:
• Can be applied to non-stationary time series. While asset returns are generally stationary, DFA can measure Hurst more accurately in the instances where they are non-stationary.
• According the the asymptotic distribution value of DFA and RS, the latter usually overestimates Hurst exponent (even after Anis- Llyod correction) resulting in the expected value of RS Hurst being close to 0.54, instead of the 0.5 that it should be. Therefore it's harder to determine the autocorrelation based on the expected value. The expected value is significantly closer to 0.5 making that threshold much more useful, using the DFA method on the Hurst Exponent (HE).
• Lastly, DFA requires lower sample size relative to the RS method. While the RS method generally requires thousands of observations to reduce the variance of HE, DFA only needs a sample size greater than a hundred to accomplish the above mentioned.
█ Calculation
DFA is a modified root-mean-squares (RMS) analysis of a random walk. In short, DFA computes the RMS error of linear fits over progressively larger bins (non-overlapped “boxes” of similar size) of an integrated time series.
Our signal time series is the log returns. First we subtract the mean from the log return to calculate the demeaned returns. Then, we calculate the cumulative sum of demeaned returns resulting in the cumulative sum being mean centered and we can use the DFA method on this. The subtraction of the mean eliminates the “global trend” of the signal. The advantage of applying scaling analysis to the signal profile instead of the signal, allows the original signal to be non-stationary when needed. (For example, this process converts an i.i.d. white noise process into a random walk.)
We slice the cumulative sum into windows of equal space and run linear regression on each window to measure the linear trend. After we conduct each linear regression. We detrend the series by deducting the linear regression line from the cumulative sum in each windows. The fluctuation is the difference between cumulative sum and regression.
We use different windows sizes on the same cumulative sum series. The window sizes scales are log spaced. Eg: powers of 2, 2,4,8,16... This is where the scale free measurements come in, how we measure the fractal nature and self similarity of the time series, as well as how the well smaller scale represent the larger scale.
As the window size decreases, we uses more regression lines to measure the trend. Therefore, the fitness of regression should be better with smaller fluctuation. It allows one to zoom into the “picture” to see the details. The linear regression is like rulers. If you use more rulers to measure the smaller scale details you will get a more precise measurement.
The exponent we are measuring here is to determine the relationship between the window size and fitness of regression (the rate of change). The more complex the time series are the more it will depend on decreasing window sizes (using more linear regression lines to measure). The less complex or the more trend in the time series, it will depend less. The fitness is calculated by the average of root mean square errors (RMS) of regression from each window.
Root mean Square error is calculated by square root of the sum of the difference between cumulative sum and regression. The following chart displays average RMS of different window sizes. As the chart shows, values for smaller window sizes shows more details due to higher complexity of measurements.
The last step is to measure the exponent. In order to measure the power law exponent. We measure the slope on the log-log plot chart. The x axis is the log of the size of windows, the y axis is the log of the average RMS. We run a linear regression through the plotted points. The slope of regression is the exponent. It's easy to see the relationship between RMS and window size on the chart. Larger RMS equals less fitness of the regression. We know the RMS will increase (fitness will decrease) as we increases window size (use less regressions to measure), we focus on the rate of RMS increasing (how fast) as window size increases.
If the slope is < 0.5, It means the rate of of increase in RMS is small when window size increases. Therefore the fit is much better when it's measured by a large number of linear regression lines. So the series is more complex. (Mean reversion, negative autocorrelation).
If the slope is > 0.5, It means the rate of increase in RMS is larger when window sizes increases. Therefore even when window size is large, the larger trend can be measured well by a small number of regression lines. Therefore the series has a trend with positive autocorrelation.
If the slope = 0.5, It means the series follows a random walk.
█ FEATURES
• Sample Size is the lookback period for calculation. Even though DFA requires a lower sample size than RS, a sample size larger > 50 is recommended for accurate measurement.
• When a larger sample size is used (for example = 1000 lookback length), the loading speed may be slower due to a longer calculation. Date Range is used to limit numbers of historical calculation bars. When loading speed is too slow, change the data range "all" into numbers of weeks/days/hours to reduce loading time. (Credit to allanster)
• “show filter” option applies a smoothing moving average to smooth the exponent.
• Log scale is my work around for dynamic log space scaling. Traditionally the smallest log space for bars is power of 2. It requires at least 10 points for an accurate regression, resulting in the minimum lookback to be 1024. I made some changes to round the fractional log space into integer bars requiring the said log space to be less than 2.
• For a more accurate calculation a larger "Base Scale" and "Max Scale" should be selected. However, when the sample size is small, a larger value would cause issues. Therefore, a general rule to be followed is: A larger "Base Scale" and "Max Scale" should be selected for a larger the sample size. It is recommended for the user to try and choose a larger scale if increasing the value doesn't cause issues.
The following chart shows the change in value using various scales. As shown, sometimes increasing the value makes the value itself messy and overshoot.
When using the lowest scale (4,2), the value seems stable. When we increase the scale to (8,2), the value is still alright. However, when we increase it to (8,4), it begins to look messy. And when we increase it to (16,4), it starts overshooting. Therefore, (8,2) seems to be optimal for our use.
█ How to Use
Similar to Hurst Exponent (Simple). 0.5 is a level for determine long term memory.
• In the efficient market hypothesis, market follows a random walk and Hurst exponent should be 0.5. When Hurst Exponent is significantly different from 0.5, the market is inefficient.
• When Hurst Exponent is > 0.5. Positive Autocorrelation. Market is Trending. Positive returns tend to be followed by positive returns and vice versa.
• Hurst Exponent is < 0.5. Negative Autocorrelation. Market is Mean reverting. Positive returns trends to follow by negative return and vice versa.
However, we can't really tell if the Hurst exponent value is generated by random chance by only looking at the 0.5 level. Even if we measure a pure random walk, the Hurst Exponent will never be exactly 0.5, it will be close like 0.506 but not equal to 0.5. That's why we need a level to tell us if Hurst Exponent is significant.
So we also computed the 95% confidence interval according to Monte Carlo simulation. The confidence level adjusts itself by sample size. When Hurst Exponent is above the top or below the bottom confidence level, the value of Hurst exponent has statistical significance. The efficient market hypothesis is rejected and market has significant inefficiency.
The state of market is painted in different color as the following chart shows. The users can also tell the state from the table displayed on the right.
An important point is that Hurst Value only represents the market state according to the past value measurement. Which means it only tells you the market state now and in the past. If Hurst Exponent on sample size 100 shows significant trend, it means according to the past 100 bars, the market is trending significantly. It doesn't mean the market will continue to trend. It's not forecasting market state in the future.
However, this is also another way to use it. The market is not always random and it is not always inefficient, the state switches around from time to time. But there's one pattern, when the market stays inefficient for too long, the market participants see this and will try to take advantage of it. Therefore, the inefficiency will be traded away. That's why Hurst exponent won't stay in significant trend or mean reversion too long. When it's significant the market participants see that as well and the market adjusts itself back to normal.
The Hurst Exponent can be used as a mean reverting oscillator itself. In a liquid market, the value tends to return back inside the confidence interval after significant moves(In smaller markets, it could stay inefficient for a long time). So when Hurst Exponent shows significant values, the market has just entered significant trend or mean reversion state. However, when it stays outside of confidence interval for too long, it would suggest the market might be closer to the end of trend or mean reversion instead.
Larger sample size makes the Hurst Exponent Statistics more reliable. Therefore, if the user want to know if long term memory exist in general on the selected ticker, they can use a large sample size and maximize the log scale. Eg: 1024 sample size, scale (16,4).
Following Chart is Bitcoin on Daily timeframe with 1024 lookback. It suggests the market for bitcoin tends to have long term memory in general. It generally has significant trend and is more inefficient at it's early stage.

Fast Autocorrelation Estimator█ Overview:
The Fast ACF and PACF Estimation indicator efficiently calculates the autocorrelation function (ACF) and partial autocorrelation function (PACF) using an online implementation. It helps traders identify patterns and relationships in financial time series data, enabling them to optimize their trading strategies and make better-informed decisions in the markets.
█ Concepts:
Autocorrelation, also known as serial correlation, is the correlation of a signal with a delayed copy of itself as a function of delay.
This indicator displays autocorrelation based on lag number. The autocorrelation is not displayed based over time on the x-axis. It's based on the lag number which ranges from 1 to 30. The calculations can be done with "Log Returns", "Absolute Log Returns" or "Original Source" (the price of the asset displayed on the chart).
When calculating autocorrelation, the resulting value will range from +1 to -1, in line with the traditional correlation statistic. An autocorrelation of +1 represents a perfect correlation (an increase seen in one time series leads to a proportionate increase in the other time series). An autocorrelation of -1, on the other hand, represents a perfect inverse correlation (an increase seen in one time series results in a proportionate decrease in the other time series). Lag number indicates which historical data point is autocorrelated. For example, if lag 3 shows significant autocorrelation, it means current data is influenced by the data three bars ago.
The Fast Online Estimation of ACF and PACF Indicator is a powerful tool for analyzing the linear relationship between a time series and its lagged values in TradingView. The indicator implements an online estimation of the Autocorrelation Function (ACF) and the Partial Autocorrelation Function (PACF) up to 30 lags, providing a real-time assessment of the underlying dependencies in your time series data. The Autocorrelation Function (ACF) measures the linear relationship between a time series and its lagged values, capturing both direct and indirect dependencies. The Partial Autocorrelation Function (PACF) isolates the direct dependency between the time series and a specific lag while removing the effect of any indirect dependencies.
This distinction is crucial in understanding the underlying relationships in time series data and making more informed decisions based on those relationships. For example, let's consider a time series with three variables: A, B, and C. Suppose that A has a direct relationship with B, B has a direct relationship with C, but A and C do not have a direct relationship. The ACF between A and C will capture the indirect relationship between them through B, while the PACF will show no significant relationship between A and C, as it accounts for the indirect dependency through B. Meaning that when ACF is significant at for lag 5, the dependency detected could be caused by an observation that came in between, and PACF accounts for that. This indicator leverages the Fast Moments algorithm to efficiently calculate autocorrelations, making it ideal for analyzing large datasets or real-time data streams. By using the Fast Moments algorithm, the indicator can quickly update ACF and PACF values as new data points arrive, reducing the computational load and ensuring timely analysis. The PACF is derived from the ACF using the Durbin-Levinson algorithm, which helps in isolating the direct dependency between a time series and its lagged values, excluding the influence of other intermediate lags.
█ How to Use the Indicator:
Interpreting autocorrelation values can provide valuable insights into the market behavior and potential trading strategies.
When applying autocorrelation to log returns, and a specific lag shows a high positive autocorrelation, it suggests that the time series tends to move in the same direction over that lag period. In this case, a trader might consider using a momentum-based strategy to capitalize on the continuation of the current trend. On the other hand, if a specific lag shows a high negative autocorrelation, it indicates that the time series tends to reverse its direction over that lag period. In this situation, a trader might consider using a mean-reversion strategy to take advantage of the expected reversal in the market.
ACF of log returns:
Absolute returns are often used to as a measure of volatility. There is usually significant positive autocorrelation in absolute returns. We will often see an exponential decay of autocorrelation in volatility. This means that current volatility is dependent on historical volatility and the effect slowly dies off as the lag increases. This effect shows the property of "volatility clustering". Which means large changes tend to be followed by large changes, of either sign, and small changes tend to be followed by small changes.
ACF of absolute log returns:
Autocorrelation in price is always significantly positive and has an exponential decay. This predictably positive and relatively large value makes the autocorrelation of price (not returns) generally less useful.
ACF of price:
█ Significance:
The significance of a correlation metric tells us whether we should pay attention to it. In this script, we use 95% confidence interval bands that adjust to the size of the sample. If the observed correlation at a specific lag falls within the confidence interval, we consider it not significant and the data to be random or IID (identically and independently distributed). This means that we can't confidently say that the correlation reflects a real relationship, rather than just random chance. However, if the correlation is outside of the confidence interval, we can state with 95% confidence that there is an association between the lagged values. In other words, the correlation is likely to reflect a meaningful relationship between the variables, rather than a coincidence. A significant difference in either ACF or PACF can provide insights into the underlying structure of the time series data and suggest potential strategies for traders. By understanding these complex patterns, traders can better tailor their strategies to capitalize on the observed dependencies in the data, which can lead to improved decision-making in the financial markets.
Significant ACF but not significant PACF: This might indicate the presence of a moving average (MA) component in the time series. A moving average component is a pattern where the current value of the time series is influenced by a weighted average of past values. In this case, the ACF would show significant correlations over several lags, while the PACF would show significance only at the first few lags and then quickly decay.
Significant PACF but not significant ACF: This might indicate the presence of an autoregressive (AR) component in the time series. An autoregressive component is a pattern where the current value of the time series is influenced by a linear combination of past values at specific lags.
Often we find both significant ACF and PACF, in that scenario simply and AR or MA model might not be sufficient and a more complex model such as ARMA or ARIMA can be used.
█ Features:
Source selection: User can choose either 'Log Returns' , 'Absolute Returns' or 'Original Source' for the input data.
Autocorrelation Selection: User can choose either 'ACF' or 'PACF' for the plot selection.
Plot Selection: User can choose either 'Autocorrelarrogram' or 'Historical Autocorrelation' for plotting the historical autocorrelation at a specified lag.
Max Lag: User can select the maximum number of lags to plot.
Precision: User can set the number of decimal points to display in the plot.
